
👋 About Me
I am a second-year master student at Shenzhen International Graduate School, Tsinghua University. I am fortunate to be supervised by Prof. Yansong Tang in IVG@SZ group. Before that, I got B.S. in Electric and Electronic Engineering from the University of Electronic Science and Technology of China (UESTC) in 2024.
My research interests lie in Computer Vision, such as Lagre Vision-Language Model, Tool-calling, Multimodal Learning, Segmentation, and Tracking.
✨ News
- 2026-02: One paper on Reasoning-Driven Multimodal Embeddings is available on arXiv
- 2025-12: One paper on Tool-Refined Visual Grounding is available on arXiv
- 2025-02: One paper on Triple Modalality Referring Segmentation is accepted to CVPR 2025
- 2024-12: One paper on Referring Image Segmentation is accepted to AAAI 2025
- 2024-07: One paper on Multimodal Learning is accepted to ECCV 2024
🔬 Research
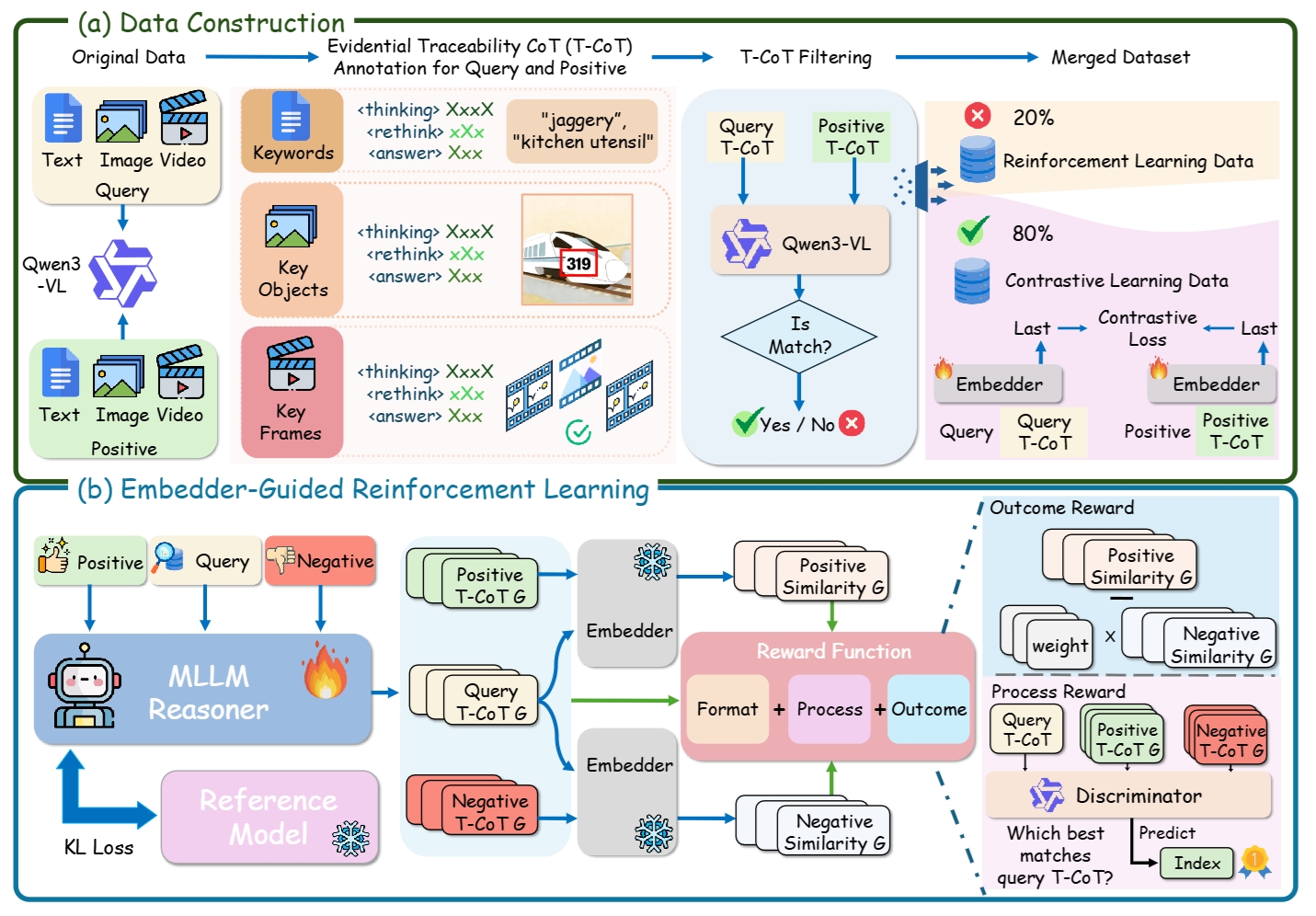 | Haonan Jiang*, Yuji Wang*, Yongjie Zhu, Xin Lu, Wenyu Qin, Meng Wang, Pengfei Wan, Yansong Tang arXiv preprint, 2026 [PDF] [Project Page] We propose Embed-RL, a reasoning-driven universal multimodal embedding framework that uses Embedder-Guided Reinforcement Learning to generate retrieval-relevant Traceable Chain-of-Thought, significantly outperforming existing models on MMEB-V2 and UVRB benchmarks. |
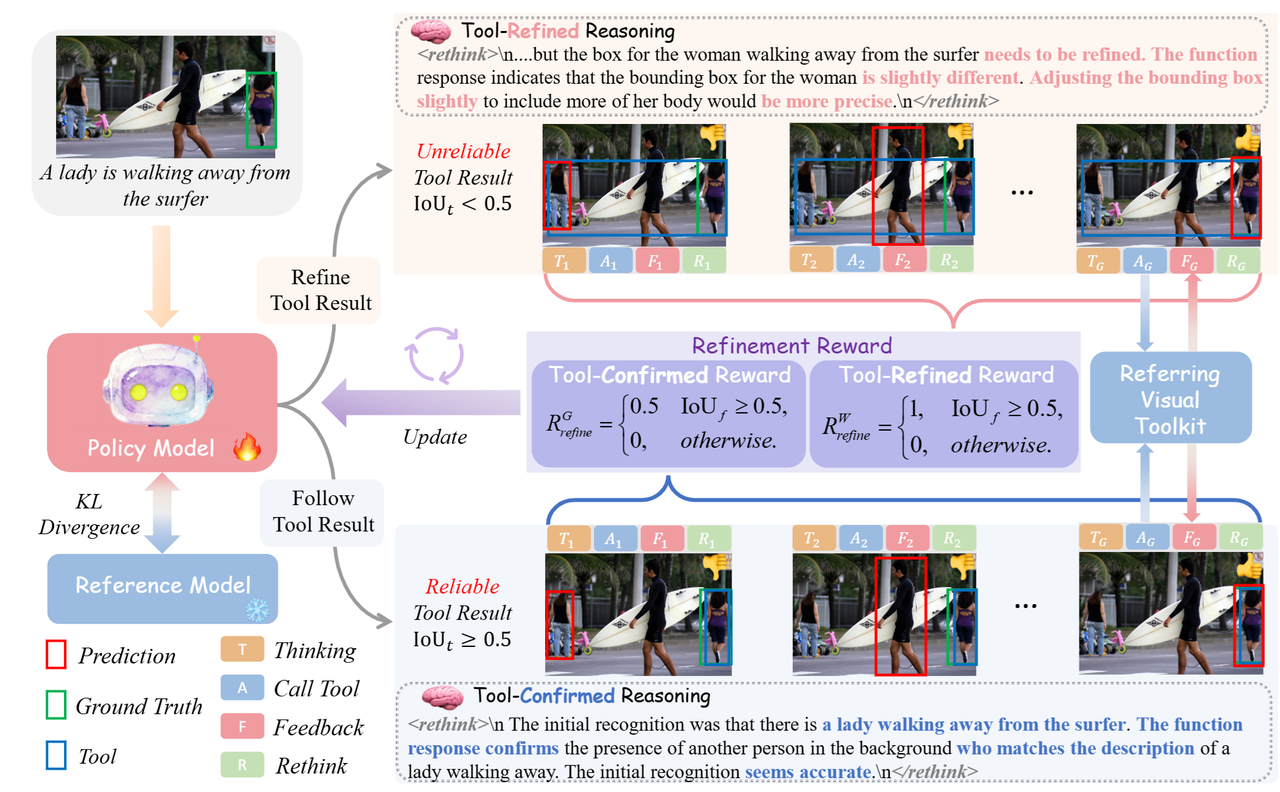 | Yuji Wang, Wenlong Liu, Jingxuan Niu, Haoji Zhang, Yansong Tang arXiv preprint, 2025 [PDF] [Project Page] We propose VG-Refiner, the first framework for tool-refined referring grounded reasoning with a two-stage think-rethink mechanism and refinement reward to handle unreliable tool outputs. |
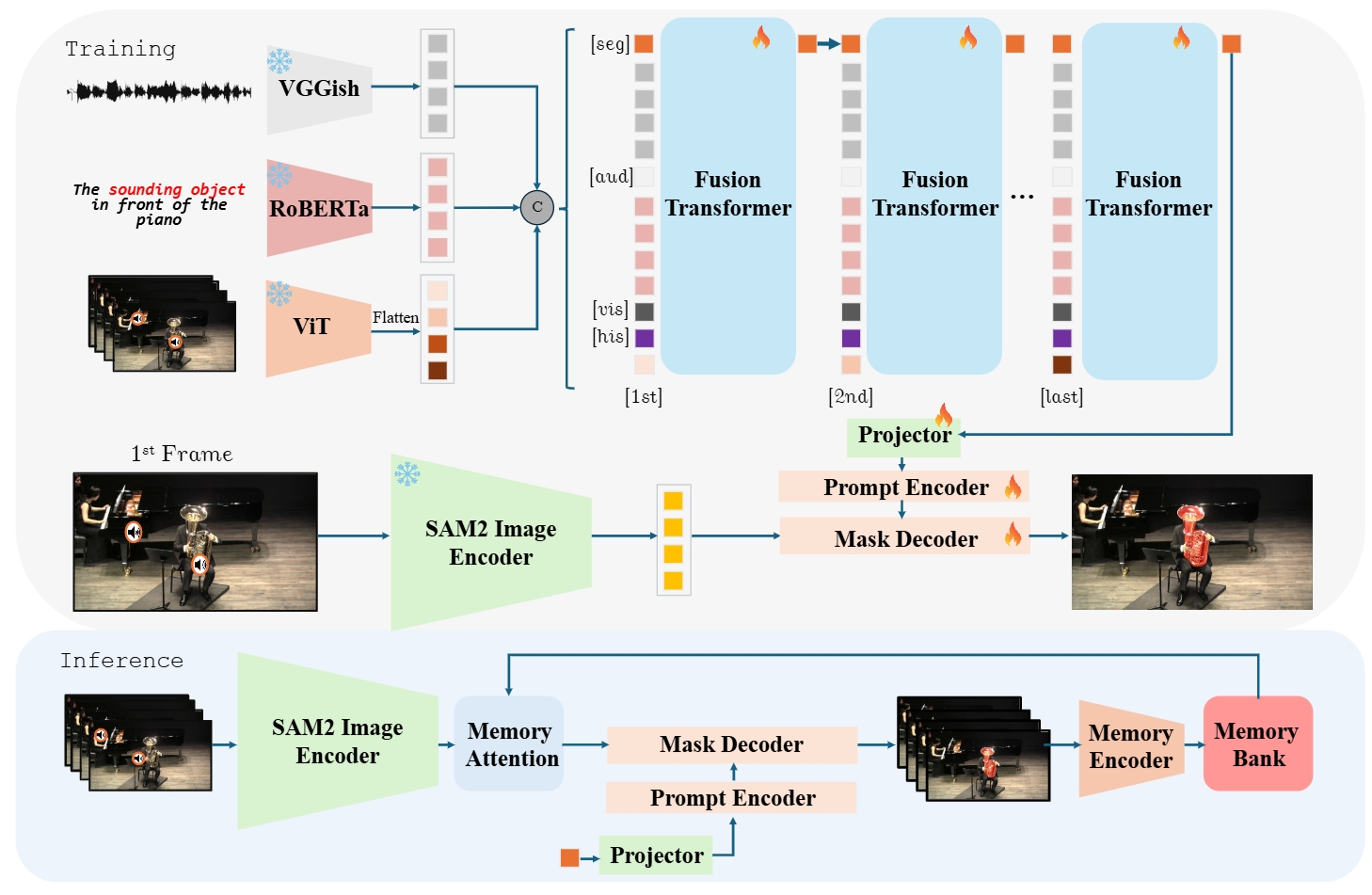 | Yuji Wang*, Haoran Xu*, Yong Liu, Jiaze Li, Yansong Tang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [PDF] [Project Page] We propose a novel framework called SAM2-LOVE to effectively segment the video objects referred by the audio and text and achieve significant improvement in Ref-AVS tasks. |
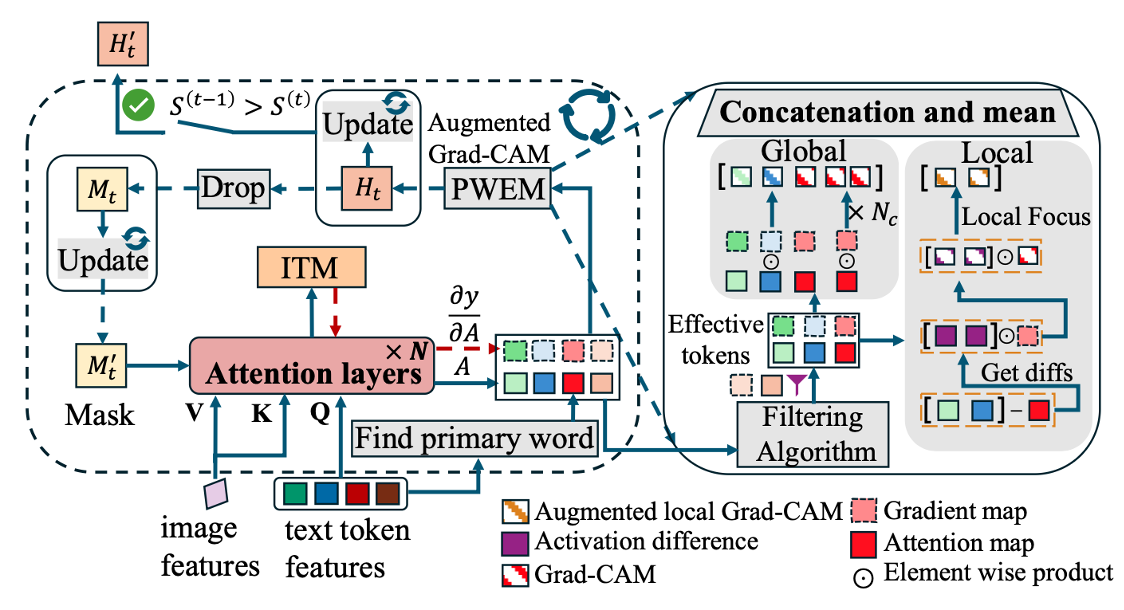 | Yuji Wang*, Jingchen Ni*, Yong Liu, Chun Yuan, Yansong Tang AAAI Conference on Artificial Intelligence (AAAI), 2025 [PDF] [Project Page] We propose the novel IteRPrimE network to leverage the Grad-CAM for zero-shot referring image segmentation, which addresses the previous CLIP-based methods' low robustness of positional phrases. |
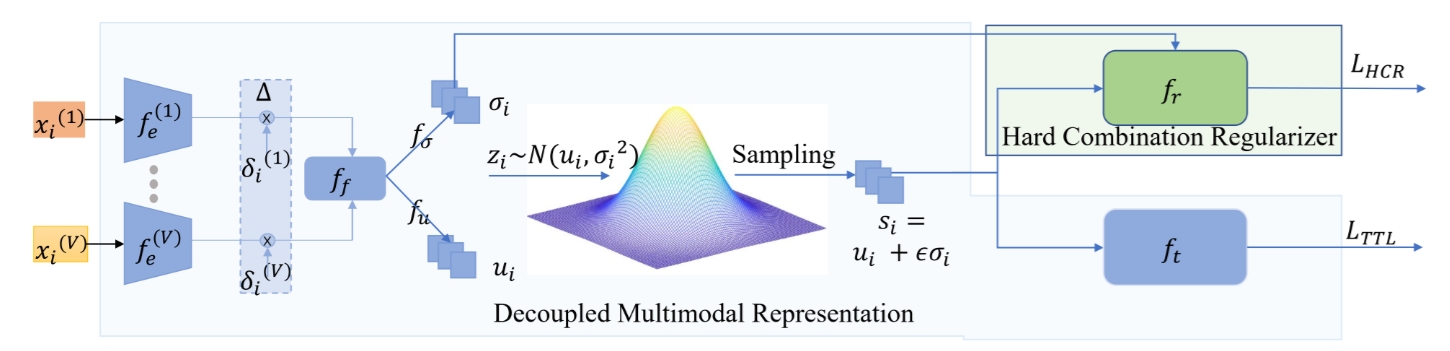 | Shicai Wei, Yang Luo, Yuji Wang, Chunbo Luo European Conference on Computer Vision (ECCV), 2024 [PDF] [Project Page] We propose DMRNet improves multimodal learning with missing modalities by modeling inputs as probabilistic distributions to capture modality-specific information, outperforming state-of-the-art methods. |
💼 Internship
 |
 |
🏆 Selected Honors and Awards
- Second-Class Academic Scholarship. Tsinghua University, 2025.11
- National Scholarship for Undergraduate Students, 2022.12, 2023.12
- First-Class Academic Scholarship, UESTC 2021.12, 2022.12, 2023.12
- Outstanding Graduate, UESTC, 2024.06
- Outstanding Graduation Thesis, UESTC, 2024.06
- First-Class Honor Degree, UESTC, 2024.06
👥 Visitors
